Regular Expressions (RegEx) Python




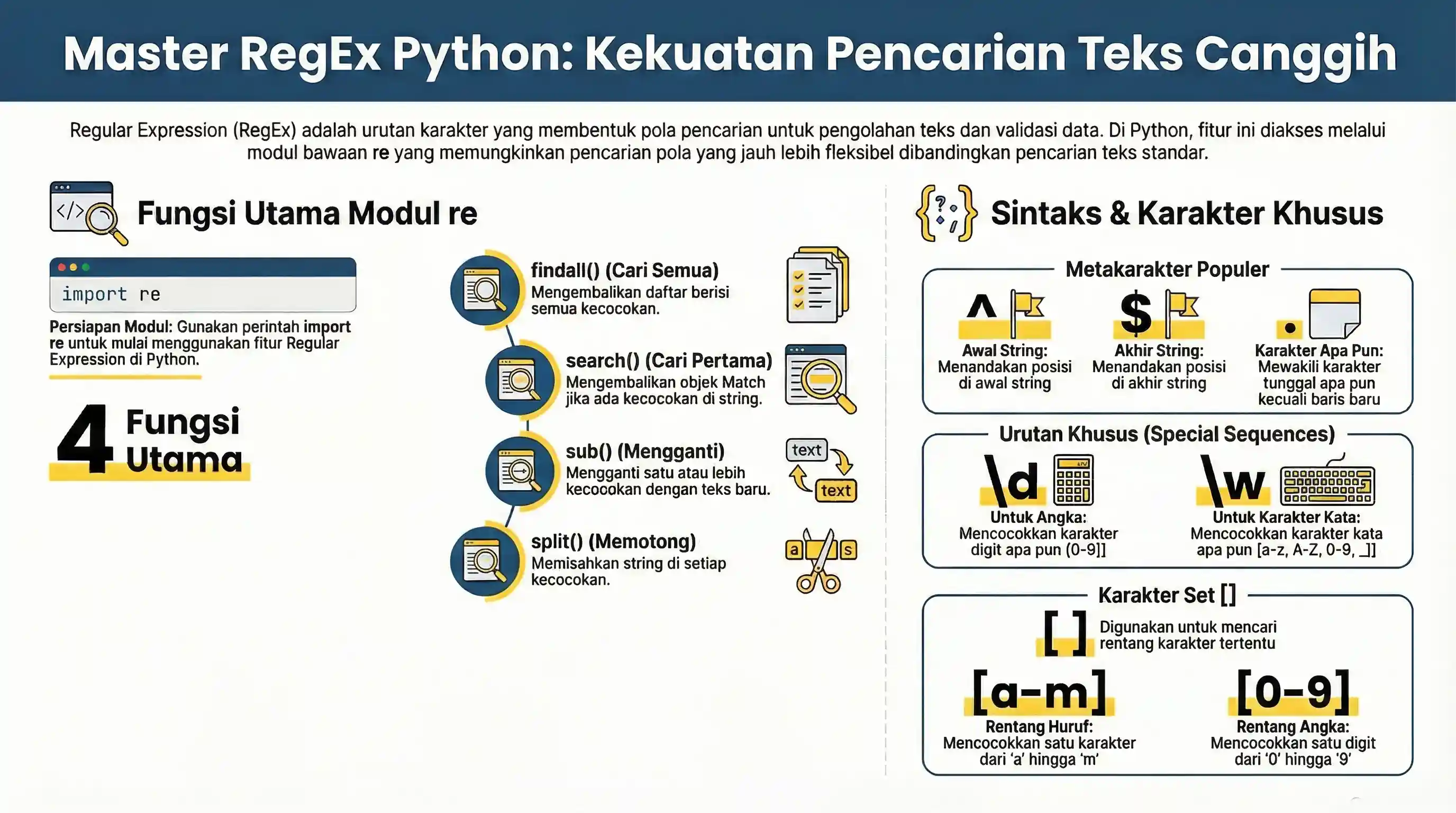
Regular Expression atau RegEx adalah urutan karakter yang membentuk pola pencarian. RegEx dapat digunakan untuk memeriksa apakah sebuah string berisi pola pencarian yang ditentukan.
Bagi pemula, bayangkan RegEx sebagai fitur "Search" atau "Find" (Ctrl+F) yang jauh lebih canggih. Jika fitur pencarian biasa hanya bisa mencari kata yang persis sama, RegEx memungkinkan Anda mencari pola tertentu, seperti mencari semua nomor telepon, alamat email, atau format tanggal dalam sebuah dokumen yang sangat panjang tanpa harus tahu isi teksnya secara spesifik.
Meskipun pada awalnya RegEx terlihat membingungkan karena penuh dengan simbol-simbol unik, menguasai teknik ini akan sangat membantu Anda dalam mengolah data teks (text processing) dan melakukan validasi input pengguna di aplikasi Python Anda dengan jauh lebih efisien.
Python memiliki modul bawaan bernama re yang dapat digunakan untuk bekerja dengan Regular Expressions.
Menggunakan Modul re
Untuk menggunakan RegEx di Python, Anda harus mengimpor modul re:
import re
Fungsi-fungsi dalam Modul re
Modul re menawarkan sekumpulan fungsi yang memungkinkan kita mencari string untuk kecocokan:
| Fungsi | Deskripsi |
|---|---|
findall |
Mengembalikan daftar yang berisi semua kecocokan |
search |
Mengembalikan objek Match jika ada kecocokan di mana saja dalam string |
split |
Mengembalikan daftar di mana string telah dipisahkan pada setiap kecocokan |
sub |
Mengganti satu atau lebih kecocokan dengan string |
Fungsi search()
Fungsi search() mencari string untuk kecocokan, dan mengembalikan objek Match jika ada kecocokan. Jika ada lebih dari satu kecocokan, hanya kecocokan pertama yang akan dikembalikan.
import re
txt = "Hujan di Spanyol"
x = re.search("^Hujan.*Spanyol$", txt)
if x:
print("YA! Kami memiliki kecocokan!")
else:
print("Tidak ada kecocokan")
Fungsi findall()
Fungsi findall() mengembalikan daftar yang berisi semua kecocokan.
import re
txt = "Hujan di Spanyol"
x = re.findall("ai", txt)
print(x)
Daftar berisi kecocokan dalam urutan kemunculannya. Jika tidak ditemukan kecocokan, daftar kosong akan dikembalikan.
Fungsi split()
Fungsi split() mengembalikan daftar di mana string telah dipisahkan pada setiap kecocokan.
import re
txt = "Hujan di Spanyol"
x = re.split("\s", txt)
print(x)
Anda dapat mengontrol jumlah pemisahan dengan menentukan parameter maxsplit:
import re
txt = "Hujan di Spanyol"
x = re.split("\s", txt, 1)
print(x)
Fungsi sub()
Fungsi sub() mengganti kecocokan dengan teks pilihan Anda.
import re
txt = "Hujan di Spanyol"
x = re.sub("\s", "9", txt)
print(x)
Anda dapat mengontrol jumlah penggantian dengan menentukan parameter count:
import re
txt = "Hujan di Spanyol"
x = re.sub("\s", "9", txt, 2)
print(x)
Metakarakter
Metakarakter adalah karakter dengan makna khusus:
| Karakter | Deskripsi | Contoh |
|---|---|---|
[] |
Satu set karakter | "[a-m]" |
\ |
Memberi sinyal urutan khusus (bisa juga digunakan untuk escape karakter khusus) | "\d" |
. |
Karakter apa pun (kecuali karakter baris baru) | "he..o" |
^ |
Dimulai dengan | "^hello" |
$ |
Berakhir dengan | "world$" |
* |
Nol atau lebih kemunculan | "aix*" |
+ |
Satu atau lebih kemunculan | "aix+" |
{} |
Persis jumlah kemunculan yang ditentukan | "al{2}" |
| |
Salah satu dari | "falls|stays" |
() |
Grup |
Urutan Khusus (Special Sequences)
Urutan khusus adalah \ diikuti oleh salah satu karakter dalam daftar di bawah ini, dan memiliki makna khusus:
| Karakter | Deskripsi | Contoh |
|---|---|---|
\A |
Mengembalikan kecocokan jika karakter yang ditentukan berada di awal string | "\AHalo" |
\b |
Mengembalikan kecocokan di mana karakter yang ditentukan berada di awal atau di akhir kata | r"\bain" r"ain\b" |
\B |
Mengembalikan kecocokan di mana karakter yang ditentukan ada, tetapi TIDAK di awal (atau di akhir) kata | r"\Bain" r"ain\B" |
\d |
Mengembalikan kecocokan di mana string berisi digit (angka 0-9) | "\d" |
\D |
Mengembalikan kecocokan di mana string TIDAK berisi digit | "\D" |
\s |
Mengembalikan kecocokan di mana string berisi karakter spasi putih | "\s" |
\S |
Mengembalikan kecocokan di mana string TIDAK berisi karakter spasi putih | "\S" |
\w |
Mengembalikan kecocokan di mana string berisi karakter kata apa pun (a-z, 0-9, dan underscore) | "\w" |
\W |
Mengembalikan kecocokan di mana string TIDAK berisi karakter kata | "\W" |
\Z |
Mengembalikan kecocokan jika karakter yang ditentukan berada di akhir string | "Spanyol\Z" |
Set Karakter
Set adalah sekumpulan karakter di dalam sepasang tanda kurung siku [] dengan makna khusus:
| Set | Deskripsi |
|---|---|
[arn] |
Mengembalikan kecocokan di mana salah satu karakter yang ditentukan (a, r, atau n) ada |
[a-n] |
Mengembalikan kecocokan untuk karakter huruf kecil apa pun, secara abjad antara a dan n |
[^arn] |
Mengembalikan kecocokan untuk karakter apa pun KECUALI a, r, dan n |
[0123] |
Mengembalikan kecocokan di mana salah satu digit yang ditentukan (0, 1, 2, atau 3) ada |
[0-9] |
Mengembalikan kecocokan untuk digit apa pun antara 0 dan 9 |
[0-5][0-9] |
Mengembalikan kecocokan untuk angka dua digit dari 00 hingga 59 |
[a-zA-Z] |
Mengembalikan kecocokan untuk karakter apa pun secara abjad antara a dan z, huruf kecil ATAU huruf besar |
[+] |
Dalam set, +, *, ., |, (), $, {} tidak memiliki makna khusus |
Contoh
import re
# Cari string yang berisi huruf kecil antara a dan n
x = re.findall("[a-n]", txt)
print(x)
Jika tidak ditemukan kecocokan, findall() akan mengembalikan daftar kosong.
Edit tutorial ini

Nonton & Buat Short Drama AI Gratis
Platform Microdrama AI pertama di Indonesia. Nonton short drama gratis atau buat drama pendek sendiri dengan AI dalam hitungan menit, tanpa kru & kamera.
100% Gratis untuk dicoba. Bagian dari ekosistem MicroDrama Indonesia.